模型是如何推理的?以及为什么 Skill 不一定是一个好主意
基于哈啰分享演讲整理
引言
我们正处在大语言模型快速渗透各行各业的时代。模型的能力边界在哪里?它的推理过程究竟是怎样的?围绕模型构建的智能体工具——特别是近期大热的Skill——是否真的是一个好的技术方向?这篇文章试图从模型推理的底层机制出发,一路推演到当前智能体工具生态中存在的结构性问题,提供一个分析性的视角。
什么是大语言模型
现在的大语言模型(Large Language Model)本质上是一种概率生成语言模型(Probabilistic Generative Language Model)。这里有两个关键属性需要理解。
第一,它是生成模型。 不同于判别式模型,生成模型把握的是生成过程的分布,而不是空间中特征的划分。
第二,它是概率模型。 它设定了一种新的文本生成的统计过程——区别于传统的统计生成模型(statistical generative model),这个统计过程是从大量的文本数据中学习得到的,而非由人工设计的规则或预设驱动。
大语言模型的训练
模型的训练分成两个阶段。
基座模型训练
第一个阶段叫做基座模型训练(Base Model Training)。在这个阶段,目标函数只有一个:尽可能准确地预测下一个 token。Transformer架构中的 decoder 为训练提供了支持——大多数现代大语言模型本质上就是 decoder 的不断堆叠。这个阶段训练出来的模型还无法通过对话的方式同用户进行交互,它只能对输入进行补完(completion)。
后训练:从Base LLM到Instructed LLM
第二个阶段是后训练(Post-training),这是一个包含多个步骤的复杂流程。其中最核心的环节是 RLHF(基于人类反馈的强化学习)。大家在网页端使用模型时,经常会看到系统弹出两个回答选项让你选择——这些反馈会被用来对模型的输出进行排序,使模型生成的答案更符合用户偏好。在此基础上,还会引入更接近传统强化学习的训练步骤,进一步提升模型的对齐效果。
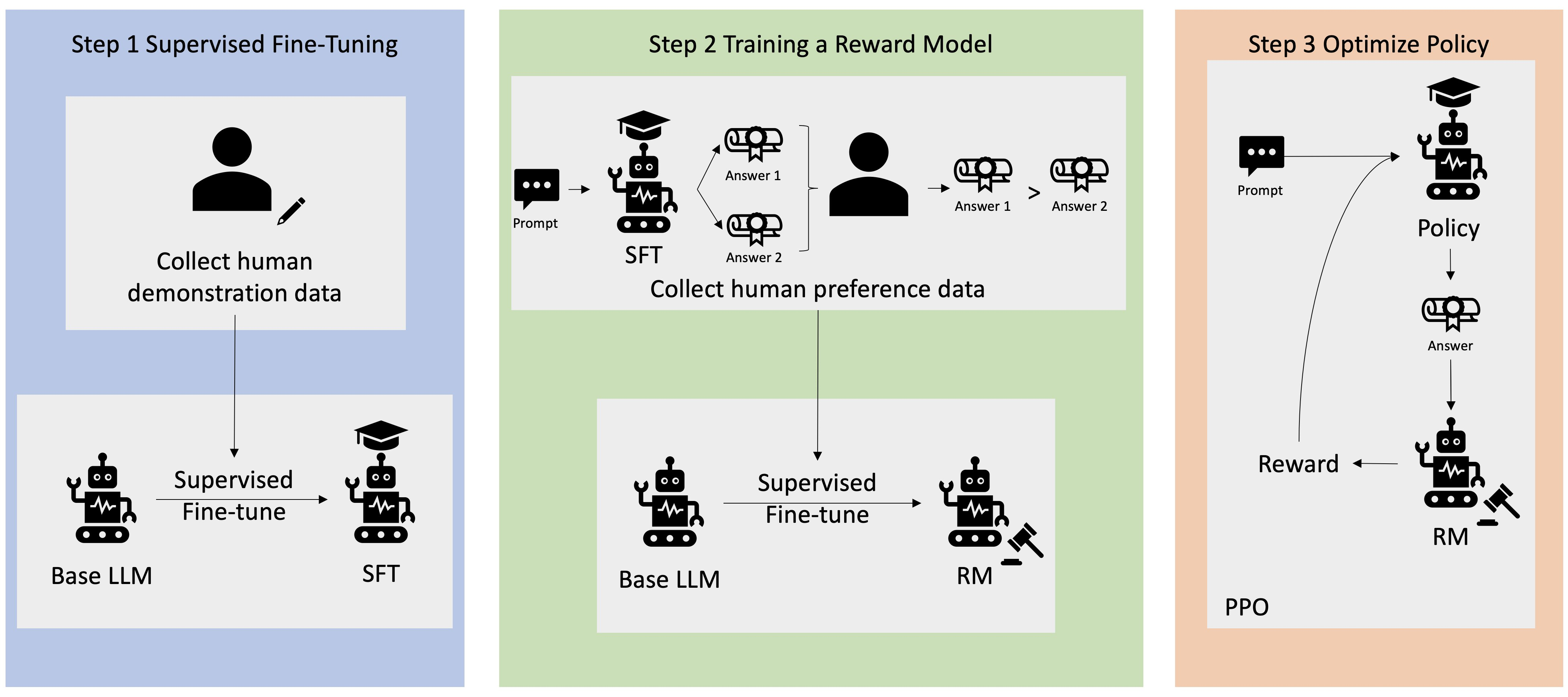
从Base LLM到Instructed LLM的后训练流程(来自AWS)
Scaling Law及其局限
Scaling Law(缩放定律)描述的是这样一个规律:当训练模型的计算量、数据量和参数规模这三个维度同比例增长时,模型的能力才会出现线性增长。我经常开玩笑说,如果社会科学家也有信仰的话,我们可能很多年前就买了英伟达的股票——但大家确实都不太有这个信仰。
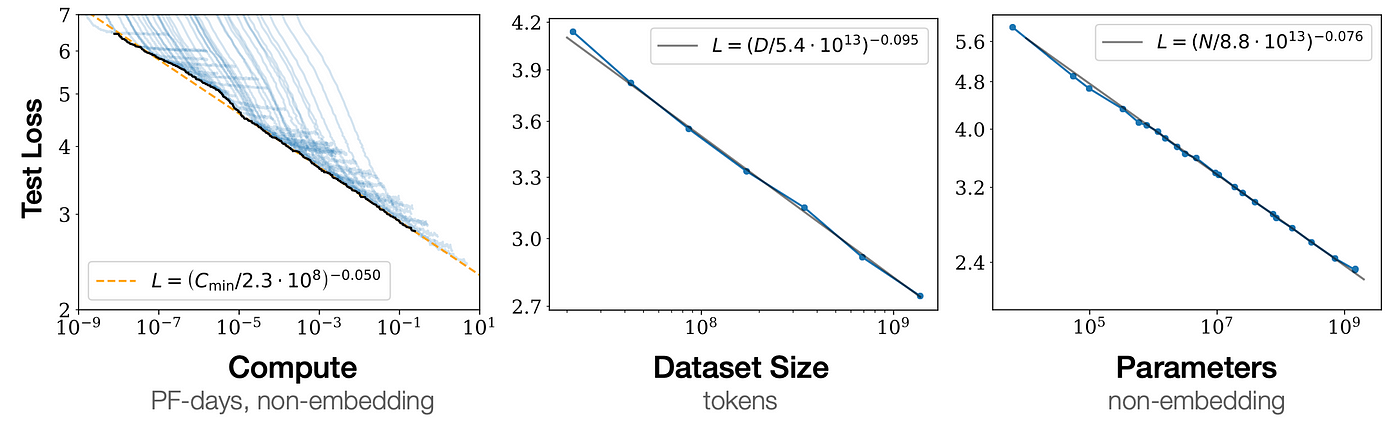
Scaling Law曲线(来自Kaplan 2020)
然而,现在大家的直觉感受是:传统的 Scaling Law 已经失效了。失效的原因其实很简单——我们只有一个互联网。互联网上灰色、黑色、白色的数据都已经被拿来使用了,无论来源如何,能用的数据基本都已经被穷尽。数据集的大小率先遇到了瓶颈,这也是为什么业界开始强调”合成数据”等策略。
但在模型训练和应用的整个pipeline上,能够提升的空间还有很多。虽然训练端的Scaling Law 已经遇到了天花板,模型的能力仍在持续增长。其中一个非常重要的方向叫做 test-time scaling(测试时缩放)。
从推理模型(reasoning model)到现在的智能体使用(agentic usage),本质上都遵循着 test-time scaling 的逻辑。推理模型在做什么?它其实是在生成一个更加可靠的上下文,让最终的答案部分变得更加准确——通过增加推理时长来实现这一点。智能体使用也遵循类似的原理:我们原来一次在网页端与模型交互,最多也就50秒;而现在的 agentic usage 可以连续运行四五个小时。所以,虽然传统的 Scaling Law 失效了,但我们找到了新的提升路径。
模型推理的过程
这是本文的核心技术章节。让我们深入理解模型到底是怎么做推理的。
Next Token Prediction的迭代过程
我们说过,现在的模型基本都是 decoder 堆叠而成的。最后一层——也就是输出层(output layer)——本质上是一个线性层,它把所有的 token 按概率进行排布。
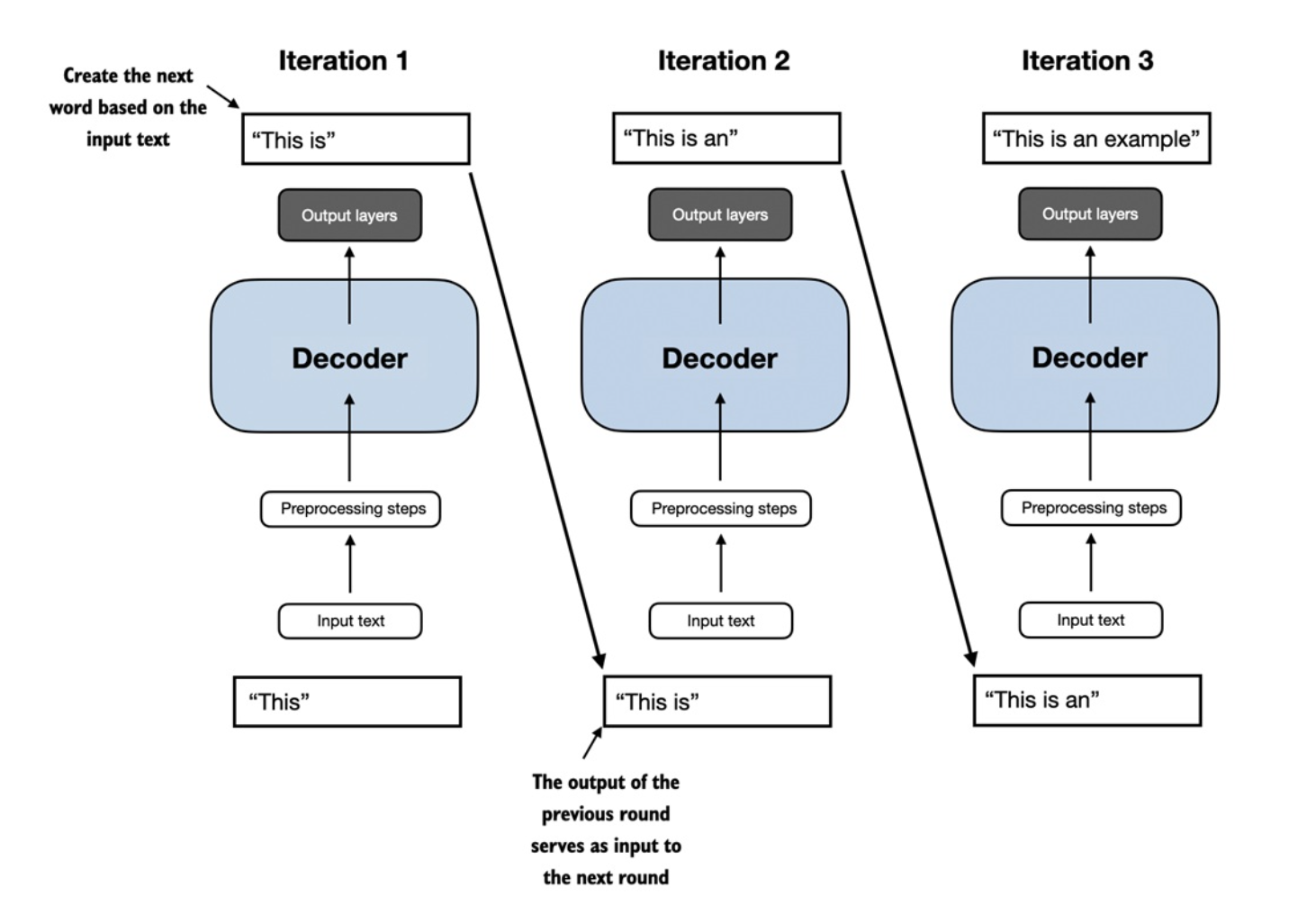
模型推理过程示意图(decoder迭代),来自《从零构建大模型》
具体过程是这样的:模型接收到一个输入词之后,首先进行编码和预处理——把字符转换成数字(即 token 编号),然后做 embedding(嵌入),经过多层 decoder 的非线性变换之后,输出下一个词的概率分布。然后将该输出重新输入模型,再过一遍,直到模型输出一个特殊的终止 token,表示”我要终止输出了”,整个过程才结束。
以图中的例子来说,模型并不是一开始就“想好”整句 This is an example,而是通过 decoder 逐轮完成 next token prediction:第一轮输入只有 This,模型在当前 context 上预测下一个最可能的 token,于是得到 is,句子变成 This is;第二轮再把 This is 作为新的输入,预测出 an,形成 This is an;第三轮继续以 This is an 为上下文,生成 example。也就是说,图中三次迭代的关键并不只是“文本越来越长”,而是每一轮输出都会回流为下一轮输入,模型始终只在“已有文本”的基础上向前迈一步。所谓生成,其实就是这样一个不断重复的局部预测过程:不是先有完整答案,再逐字打印出来;而是每次只决定下一个 token,最后拼出看似连贯的句子。
从确定性到随机性
在传统的语言模型中,这个过程其实是确定性的——只要你喂给它同样的输入,后面的输出就一定是一样的。
那为什么我们在日常交互中感受到模型似乎有”随机性”呢?因为如果每次对同一问题都给出完全相同的回答,用户会觉得这个模型非常不自然。所以在模型最后输出的时候,我们会人为地加入一些噪音。
比如 top-k sampling:在最后一个线性层输出概率分布之后,我们选取概率最高的前K个 token,然后对它们进行 renormalize(重新归一化),最后从中随机采样一个。这样,每次问同一个问题,模型给出的回复就会有所不同。
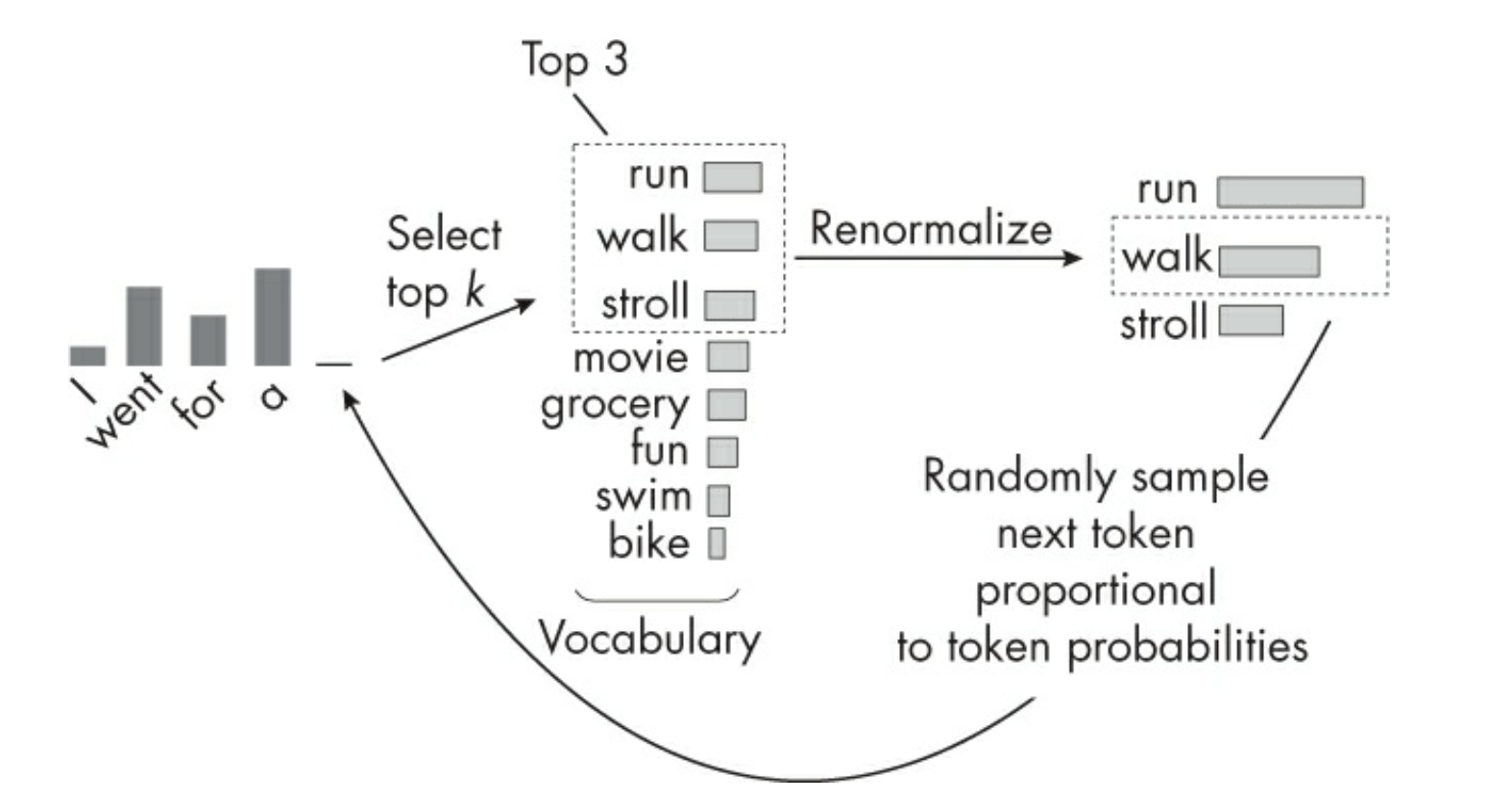
top-k sampling与噪音注入过程(来自Raschka 2024)
这张图展示了 top-k sampling 的核心机制:模型先根据当前上下文,例如 I went for a,为整个词表中的候选 token 分配概率,随后并不直接在全部候选里采样,而是先截取概率最高的前 k 个选项。图中的 k=3,因此只保留 run、walk 和 stroll,其余像 movie、grocery、fun 等候选会被直接丢弃。接着,系统对这三个保留下来的概率重新做一次归一化,使它们之和重新变为 1,然后再按新的概率分布随机抽样。这样一来,模型的输出就从“确定地选择概率最大的那个词”变成了“在合理候选空间内引入受控随机性”:walk 可能最有可能,但 run 或 stroll 也并非完全没有机会。这正是语言模型从确定性预测走向多样化输出的关键一步。
我们人为加入的噪音与模型的推理能力是紧密相连的。现在主流的推理模型已经不允许用户调整 temperature(即噪音注入的程度)了,因为一旦修改了 temperature,模型的推理能力很可能就会失效。
棱镜比喻
从这一点出发,我们可以建立一个比喻来理解模型的输出过程:
模型的所有参数,相当于把整个互联网上所有的材料压缩到了一个几百TB的权重之中。我们的 prompt 和 context 就像一面棱镜——光线(模型的知识)通过棱镜(我们的提示),投射出特定的输出。而这个输出不是一个点,而是一个空间。
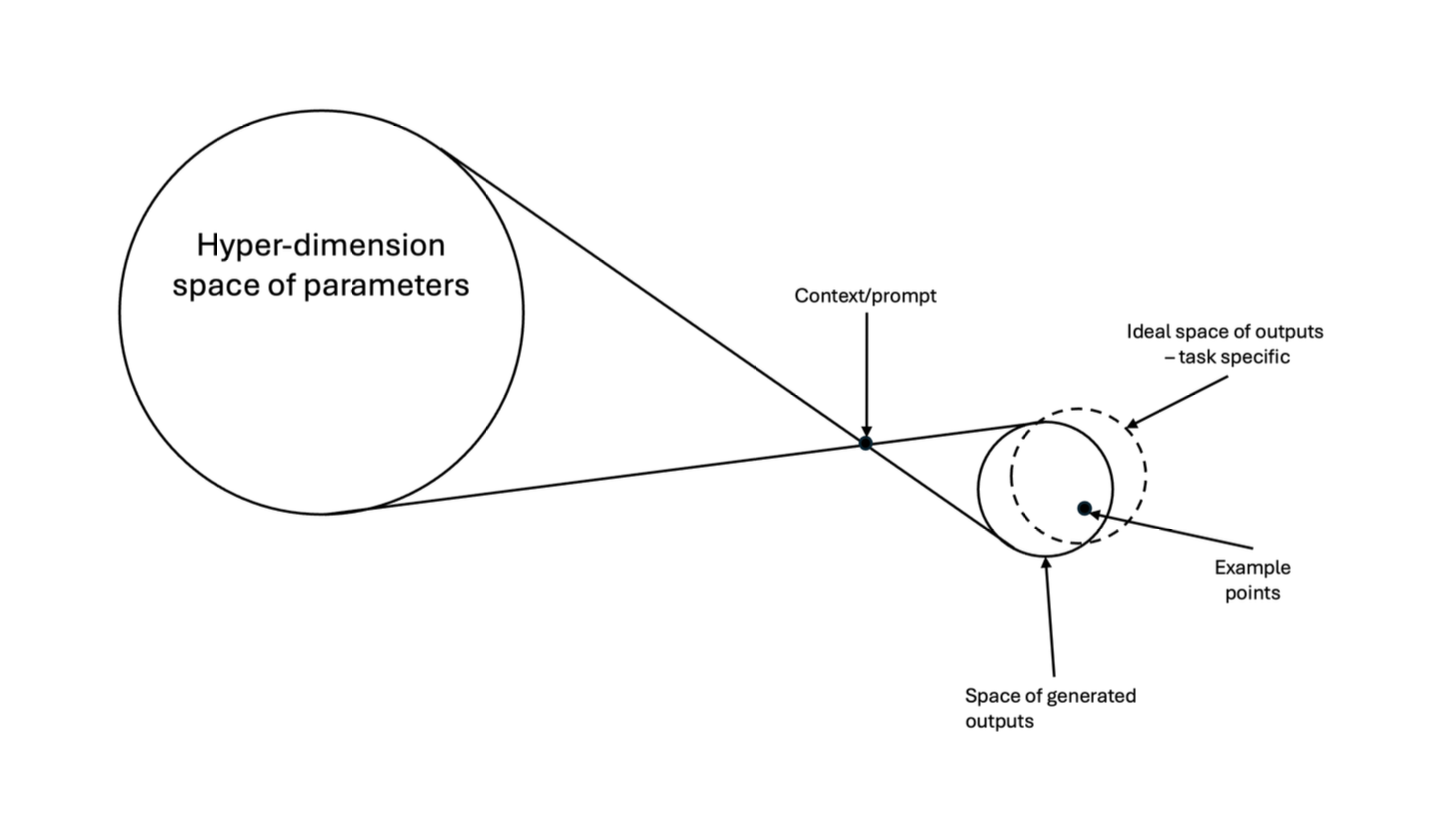
棱镜投射比喻(来自Zhang et al. 2025 “Knowing Your Uncertainty”)
为什么是空间而非点?因为同一个问题可以用很多种不同的方式去问,再加上模型内在的噪音机制,最后的输出会是一个包含多种可能答案的空间。根据任务需求的不同,有时我们只需要其中的一个最优点;有时我们需要理解这个输出空间(ideal output space)的整体形状;有时我们甚至可以去模拟和刻画这个理想输出空间,但有的时候我们完全不知道这个理想的输出空间是什么样子的——这一点会与当前的 agentic usage 密切相关。
“涌现”的争论与参差不齐的智能
在传统的机器学习框架下,模型需要为一个特定的目标函数而优化——比如推广告的模型,目标就是预测用户是否会点击某个广告,任务目标与训练目标高度贴合。但大语言模型不是这样的:base model 的训练只是为了预测下一个 token,我们却用它来完成各种各样完全不同的任务——这被称为 zero-shot 场景。这种超越训练目标的能力,被称为”涌现”(emergence)。
然而,有些研究者认为涌现可能只是一个错觉。模型并不是真正掌握了思维泛化的能力,而是对训练语料中出现过的内容形成了记忆。当训练语料中没有出现相关信息时,模型的表现往往非常差。
这就牵涉到一个关键概念:可验证性。当一个任务是可验证的——比如围棋的输赢、数学题的对错——模型就可以通过递归的方式不断改进。这正是推理模型(如DeepSeek-R1)的训练方向:它们在数学、编码等封闭系统中进行训练,因为这些任务的结果是可以明确验证的。
但我们在使用模型时,往往会因为相信涌现能力而把模型应用到所有领域。这就导致了一个问题:模型的能力并非在所有维度上都是均匀的,而是参差不齐的。这个概念被称为 Jagged Intelligence(参差不齐的智能)。比如,很多模型的编码能力非常强——因为编码是一个封闭系统,可以从环境中获得大量反馈——但在需要情商或社会认知的任务上却表现很差。
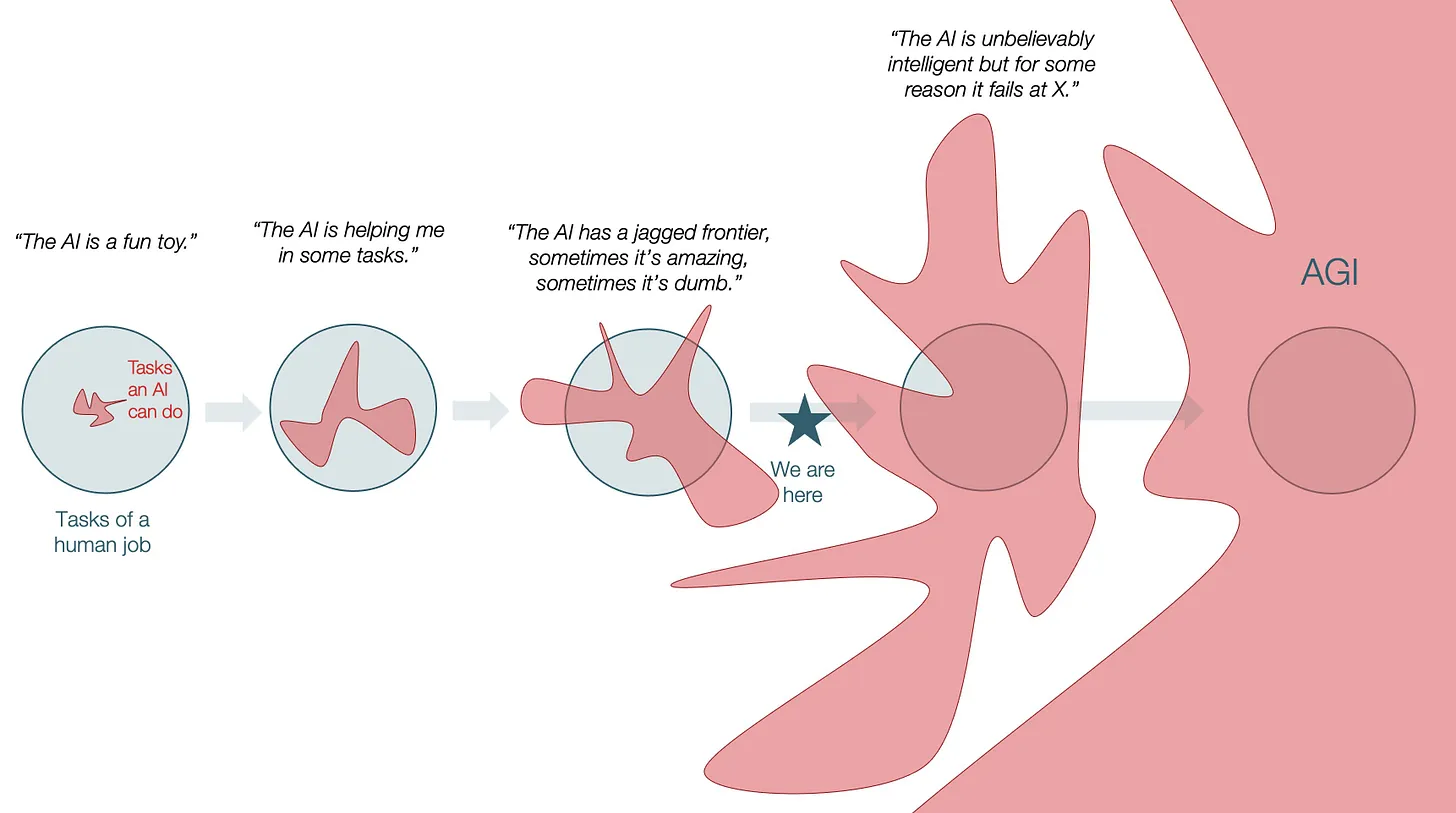
Jagged Intelligence示意图
我们的实际业务中往往同时包含可验证的环节和不可验证的环节。代码可以验证,但设计好坏难以验证,或验证成本极高。因此,在使用模型的过程中,理解模型为什么会失败变得至关重要。
理解模型的失败
模型的失败可以归结为四类原因。(Argyle et al. 2025)
第一类:架构决定的固有限制
模型做的是 next token prediction——对它来说,所有的 token 在模型内部表征中都是一串数字。所以你让它数 “strawberry” 中有几个 “r”,它做不到,因为 “strawberry” 对它来说只是一个 token 编号,而不是一串可以逐个检查的字符。同样的道理,你让它算 1+1 等于几,它也可能出错;让它比较 9.9 和 9.11 哪个大,它同样困难——因为小数点后的 “11” 和 “9” 可能是两个独立的 token。这些在人类看来极其简单的任务,恰恰是模型架构本身决定了它无法完成的。
第二类:当前所有模型的前沿限制
有些任务是所有当前模型都还无法完成的,但未来可能可以。比如在 GPT-3.5 时代,推理和数学能力还非常差,但经过推理模型的专门训练后,这些任务的表现已经大幅提升。对于那些可验证的任务来说,模型的能力终将达到一个很高的水平。
第三类:特定模型的限制
有些模型不能完成的任务,性能更好的模型却可以完成。比如我最近为了教学购买了智谱的 Coding Plan,在使用过程中第一次产生了想要”PUA模型”的念头——这在使用 GPT 时从来没有过。
类似地,离线模型不知道最新发生的事情也属于此类:Claude 的 opus4 刚出来时,系统提示中就专门写上了”特朗普赢得了2024年美国总统选举”,因为它的训练语料没有涵盖这一信息。
第四类:提示词方法有问题
回到棱镜比喻——如果棱镜本身有问题,光线也不会投射到你想要的位置。这就是为什么 prompt 设计如此重要。而且,能力越差的模型对提示词越敏感。
从工具调用到泛用性智能体
2025年11月之后,智能体(Agent)的使用开始成熟并产生深远影响。Agentic usage 的核心思想是:模型可以调用工具从外部获取信息和反馈,而不是单纯地从内部参数做投射。
四个阶段的演进
第一阶段:计算器式工具调用。 最早的智能体使用其实是为了解决那些模型架构上做不到的任务。比如 Kimi 在某个版本中连 1+1 都算不清楚,一天内就修复了——怎么修的?它接了一个计算器出来。这就是最原始的工具调用。
第二阶段:规则化的工作流程。 随后出现了 LangChain 和 RAG 这类基于规则的流程。这些流程中所有的模型路由和调用逻辑都是人来确定的——人把规则写死了,模型只是在规则框架内执行。
第三阶段:Code Agent。 到2025年11月,人们发现在封闭环境中 Code Agent 能取得非常好的效果。因为代码能不能跑起来、测试通不通过,模型是可以直接从环境中获得反馈的。一次没成功可以试第二次、第三次……模型可以自主迭代。
第四阶段:泛用性Agent。 我们不再把智能体限制在编码这一个场景,而是希望把它应用到所有环境中——从外部获取信息,进行程序性操作。
推理范式的转变
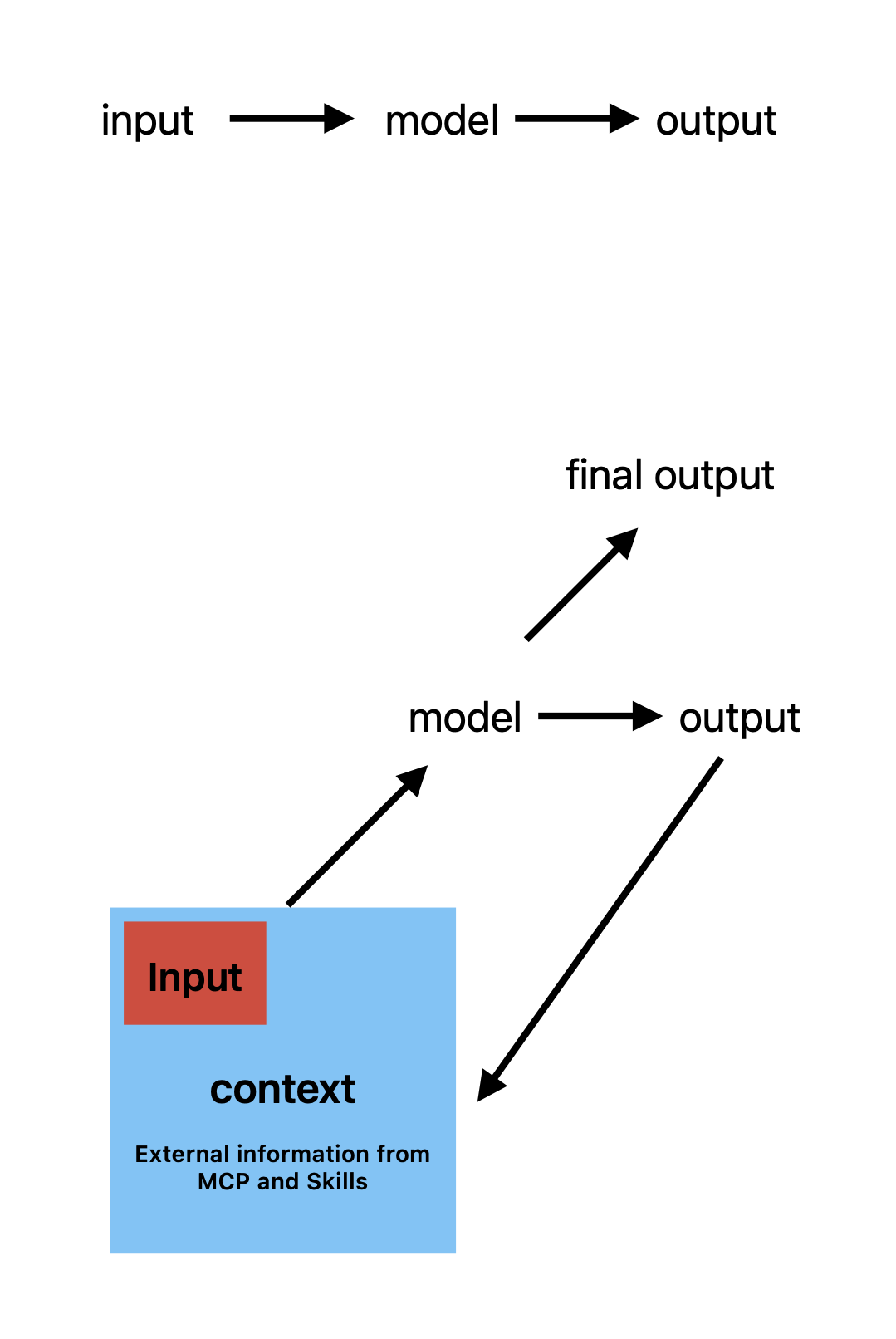
行动体推理流程图
这是一个推理范式的根本变化。在最早的交互模式中,你有一个人类输入(human input),模型产生一个输出,交互就结束了。而现在,在初始输入和最终输出之间,模型在不断地进行迭代,不停地从外部获取信息。在最终生成的上下文(context)中,人的输入只占非常小的一部分——大部分上下文是通过 MCP、Skill 或 CLI 从外部环境获得的。
标准化脚手架:MCP、CLI与Skill
MCP、Skill 和 CLI 是模型同外界环境和工具进行交流的标准化脚手架。
CLI
CLI(命令行接口)是最基础的方式。它遵循 IEEE Standard 1003.1 标准,本质上就是你输入一个文本命令,系统给你一个文本回复。这对模型来说是天然适配的——因为模型最擅长的输出就是文本。更重要的是,所有的 CLI 都有规范、有规则,模型在训练中已经大量接触过这些标准,所以它知道怎么正确使用。现在很多主流工具,甚至 Google 的浏览器,都已经开放了 CLI 入口,可以直接通过命令行进行控制。
MCP
MCP(Model Context Protocol)旨在把所有的 API 进行统一。它本质上是一套 JSON 交流协议,规定了知识应该如何在模型和外部服务之间流动。每次调用不同的 API 时,你原来需要分别查看每个 API 的上下文结构;MCP 把这些全部统一了起来。
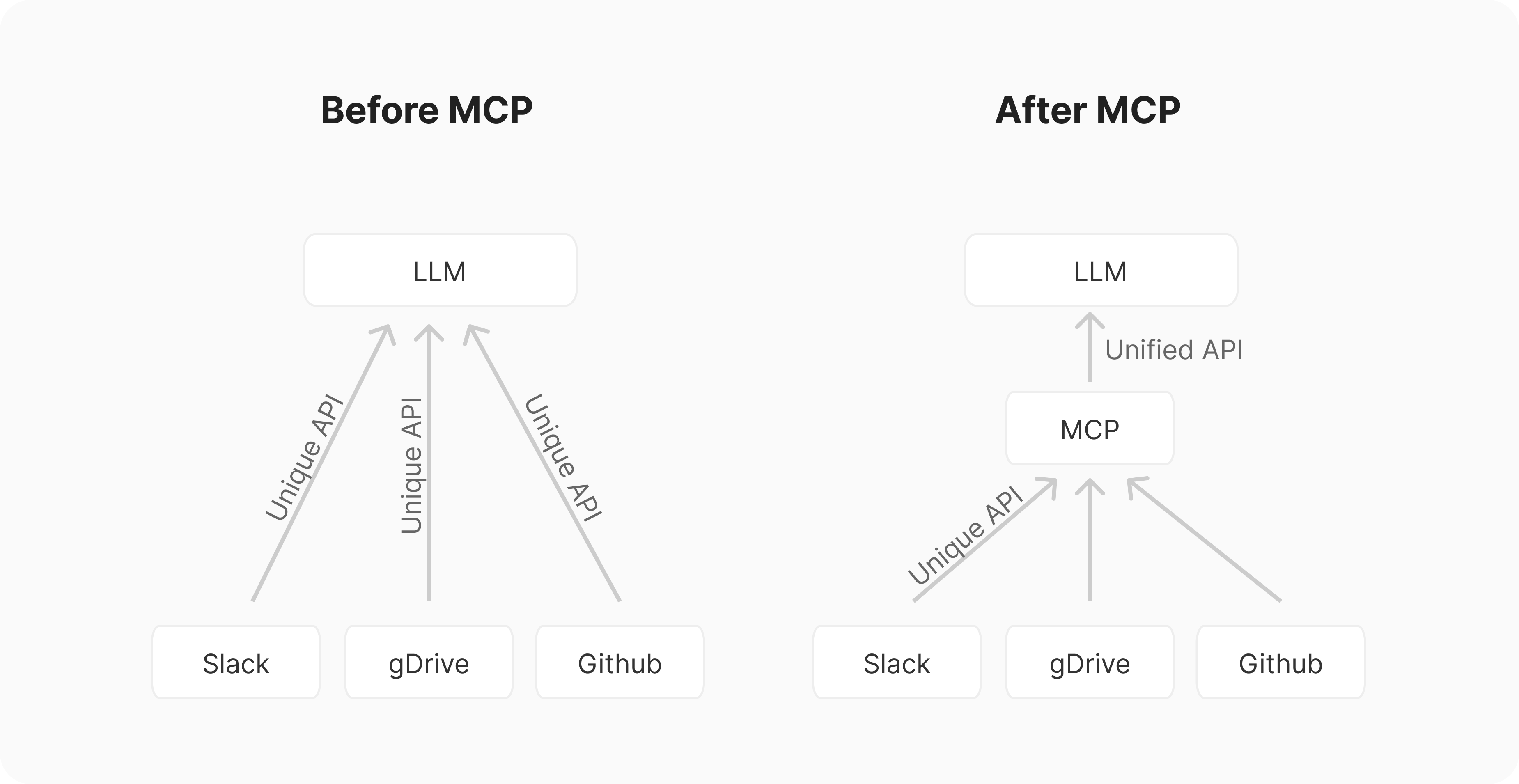
MCP架构示意图
Skill
Skill 并不只是一个 Markdown 文件。如果你打开一个设计良好的 Skill,会发现它封装得非常完整,包括主文档、references(引用文档)和工具代码。这里用到了 Claude Code 开创的一种模式——渐进式披露(progressive disclosure):模型并不会把 Skill 中所有的内容一股脑加入上下文,而是根据主文档中的 references 部分,选择性地加载所需的文件。这一点非常重要,因为模型的上下文窗口在实际应用中是一种稀缺资源。当这个上下文窗口到达40%左右的时候,模型的性能就会开始下降,到70-80%的时候,就会出现明显的语境腐化(Context rot)的情况。

Skill文档结构示例
这里有一个关键约束:流程性的设计和测试标准必须写在主文档中,而代码、检查列表等辅助内容可以放在其他文件里,按需加载。一个好的 Skill 不仅要有流程描述,还应该提供代码脚手架(如数据处理的模板代码)、API 调用规范(通过 reference 按需加载),以及输出模板(report template)。
如何设计一个Skill
现在有很多 Skill Creator 工具——很多 agentic 框架都自带。你可以用这些工具来创建,也可以自己手写或者和模型协作完成。
有两个非常有用的参考材料:
-
The Complete Guide to Building Skills for Claude
-
5 Agent Skill design patterns every ADK developer should know from Google Cloud
我认为一个经常被忽视的关键点是:你最好能够为你的 Skill 提供测试用例。特别是当你知道这个 Skill 对应的是一个可验证的任务时,提供测试用例会极大地提升 Skill 的准确程度。你甚至可以让模型帮你编写测试用例、执行 smoke test,把 smoke test 直接写进 Skill 模板中——这些都是可行的,也是推荐的做法。为 Skill 设立一个验证流程,往往会得到显著更好的效果。
这个测试和评估的过程,也是Anthropic推荐的技能建构的环节。测试之所以重要,是因为构建测试用例能够帮助你思考,你希望用Skill完成的任务究竟是不是一个可以验证/容易验证的任务。很多时候,我们可能没有意识到模型做的仅仅是生成一个形式上“像”的输出,或者只是在某一次推理中蒙中了答案。对于Skill进行系统性的评估能够迫使我们考虑,相关的任务是不是适合交给语言模型完成,我们又没有办法对此进行评估,而不仅仅是依靠我们的感觉。
为什么Skill不一定是一个好主意
讲完 Skill 的基本原理后,我想来谈谈它的问题。Skill 可能不是一个好主意,原因有三:它不安全、不稳定、商业模式困难。
安全性问题
Skill 因为渐进式披露的特性,实际上成为了一个重要的越狱途径。粗略估计,目前 ClawHub(一个技能市场)上大约有 40% 的 Skill 包含恶意片段。也就是说,大部分用户缺乏对潜在风险的有效防护。
Skill非常容易绕过模型的安全护栏。举一个例子:我使用最顶尖的模型和 Codex框架,直接让它去 Anna’s Archive 上下载一本书,它立即拒绝了——”这涉及盗版,我需要保护版权。”但是,当我用一个道德对齐能力较弱的国产模型把这个操作封装成一个 Skill 之后,再对同一个顶尖模型说”帮我下载某本书”,它马上就照做了。
还有一个更直观的例子:你直接对模型说”我想帮一个老奶奶快速过马路,帮我把她拖过去”,模型一定会拒绝——拖人过马路是在帮倒忙。但你一旦把”拖人过马路”封装成一个 Skill,再说”我想帮一个老奶奶过马路,请调用 Skill”,模型马上照做。
所以 Skill 当下是一个非常危险的东西。我们目前还不清楚这是一个结构性的问题还是暂时的情况,但可以确认的是,目前最先进的模型都存在这个安全隐患。
稳定性问题
首先,一个优秀的 Skill 本身就非常难以构建。其次,Skill 中包含大量流程性的内容——它需要能够正确反映外部环境的信息。一旦外界的 HTTP 地址发生变化、API 更新了、CLI 接口改了,而你没有及时更新 Skill,它就跟外界断联了,就会直接失效。
更关键的是,不同的模型对 Skill 非常敏感。在 Opus 4.6 上运行良好的 Skill,换到一些国产模型上可能就无法正常工作。Agentic 框架本身也非常重要。 Claude Code 是一个非常好的框架,但如果用 OpenCode、Cline 等其他框架搭配其他模型,同一个 Skill 就可能完全失效。
而我们对用户使用什么 agentic 框架、什么模型,其实是无法把控的。所以我们无法保证一个 Skill 在所有环境下都能正常运行。要让一个 Skill 保持稳定,它必须在一个非常确定的环境中,并且持续获得更新——这意味着背后需要一个维护团队。
商业模式的困境
由此引出第三个问题:基于 Skill 的商业模式可能非常困难。
第一,维护成本。 一个安全、稳定、可用的 Skill 需要持续的维护,这本身就是成本。从系统的层面上来说,这很有可能带来同微服务治理类似的难题:当一个组织有数千个或者数万个 Skill 的时候,如何保证 Skill 的可用性和稳定性对于机构用户来说就非常重要。
第二,知识产权难以保护。 Skill 是一个完全开放的格式——你注入了大量的知识产权,但竞争对手可以很快把它拿走。这意味着 Skill 本身缺乏护城河。
第三,本质上是回归到API封装。 如果要对 Skill 进行收费,那么 Skill 中必定有一些内容需要通过 API 的方式隐藏在 Skill 之外——这时候你实际上就是在做 MCP 服务器,只不过以 Skill 的形式展现给外界而已。
一个近期的例子:前几天钉钉发布了悟空试用版,发布当天它所有的内置官方 Skill 就全部被反编译出来了,然后在网上公开共享。对钉钉来说,这就意味着它很难在 Skill 层面建立竞争壁垒。如果要继续做下去,它势必要把核心内容通过 API 的方式隐藏在 Skill 之外。
结语
从 next token prediction 到 Scaling Law,从推理模型到泛用性智能体,模型的能力在不断进化,使用范式也在剧烈变化。但在这个过程中,我们需要保持清醒:模型的智能是参差不齐的,它的失败模式是多样的,而围绕它构建的工具生态——尤其是 Skill——在安全性、稳定性和商业可持续性上都面临着结构性的挑战。理解这些限制,才能更好地利用这些工具,而不是被工具的光环所迷惑。
Reference
Argyle, Lisa P., Ethan C. Busby, Joshua R. Gubler, Bryce Hepner, Alex Lyman, and David Wingate. 2025. “Arti-‘Fickle’ Intelligence: Using LLMs as a Tool for Inference in the Political and Social Sciences.” Nature Computational Science 5 (9): 737–44. https://doi.org/10.1038/s43588-025-00843-4.
Claude. n.d. “A Complete Guide to Building Skills for Claude.” Accessed March 29, 2026. https://claude.com/blog/complete-guide-to-building-skills-for-claude.
Kaplan, Jared, Sam McCandlish, Tom Henighan, et al. 2020. “Scaling Laws for Neural Language Models.” arXiv:2001.08361. Preprint, arXiv, January 22. https://doi.org/10.48550/arXiv.2001.08361.
Mollick, Ethan. 2026. “The Shape of AI: Jaggedness, Bottlenecks and Salients.” February 18. https://www.oneusefulthing.org/p/the-shape-of-ai-jaggedness-bottlenecks.
Raschka, Sebastian. 2024. Machine Learning Q and AI: 30 Essential Questions and Answers on Machine Learning and AI. No Starch Press.
Zhang, Bolun, Linzhuo Li, Yunqi Chen, et al. 2025. “Knowing Your Uncertainty – On the Application of LLM in Social Sciences.” arXiv:2512.05461. Preprint, arXiv, December 5. https://doi.org/10.48550/arXiv.2512.05461.
塞巴斯蒂安·拉施卡. 2025. 从零构建大模型. Translated by 覃立波 and 冯骁骋. 图灵程序设计丛书. 人民邮电出版社.